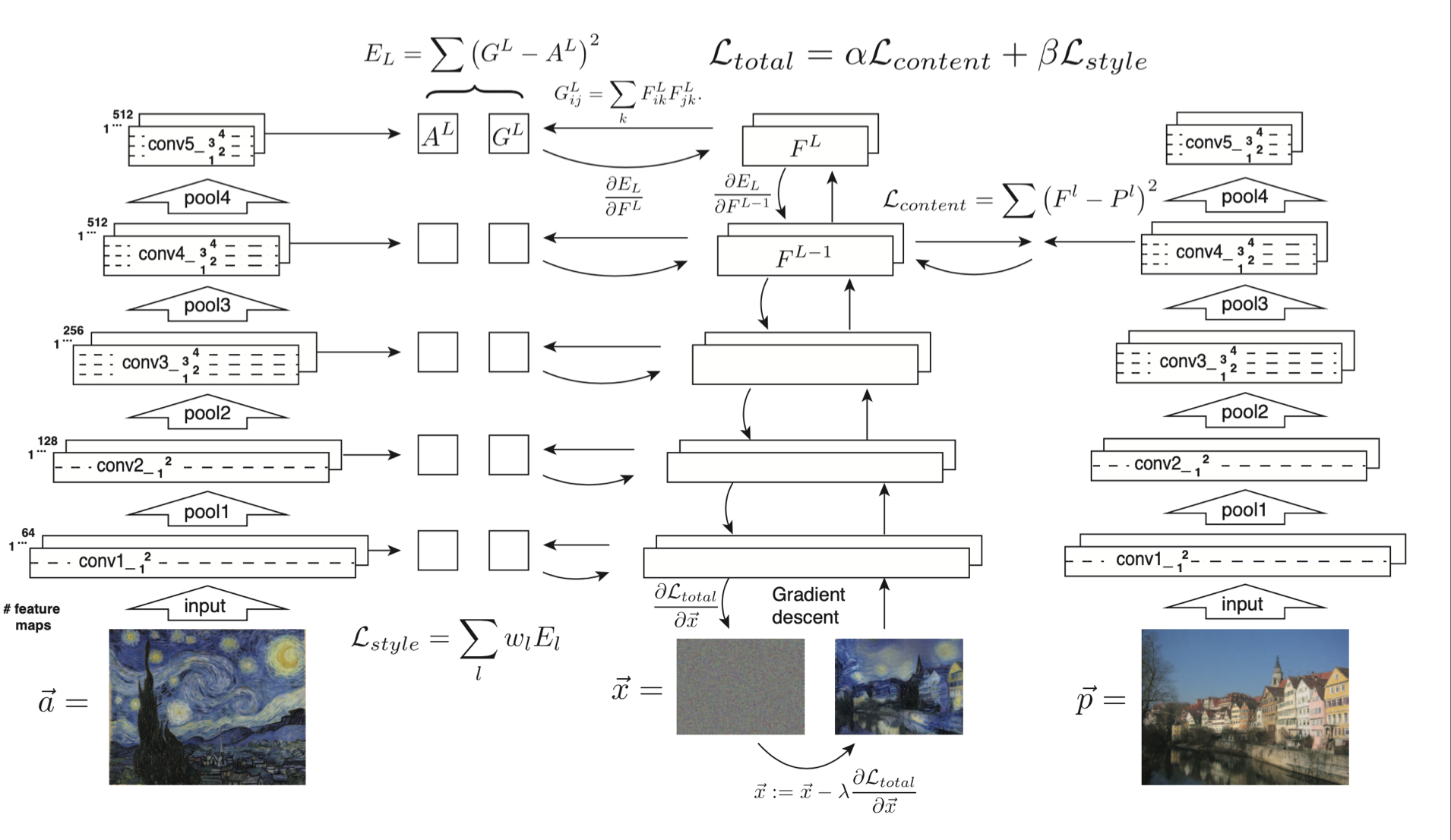
Style Transfer
We use image representations derived from CNNs optimised for object recognition,
which make high level image information explicit.
Our algorithm can separate and recombine the image content and style of images
The algorithm allows us to produce new images of high perceptual quality that
combine the content of an arbitrary photograph with the appearance of numerous
well-known artworks
Our results provide new insights into the deep image representations learned by
CNNs and demonstrate their potential for high level image synthesis and
manipulation”

The input image is transformed into representations that are increasingly sensitive to the actual content of the image, but become relatively invariant to its precise appearance. Higher layers in the network capture the high-level content in terms of objects, but do not constrain the exact pixel values of the reconstruction very much. Reconstructions from the lower layers simply reproduce the exact pixel values of the original image
The correlation matrix is sensitive****to textures (spatial patterns that happen all over the image) 
• Style feature space can be built on top of the filter responses in any layer of the network. It consists of the correlations between the different filter responses.
• Feature correlations are given by the Gram matrix G, where G’ is the inner product between the vectorized featured maps i and j in layer l: this is the sum across all pictures in the feature map
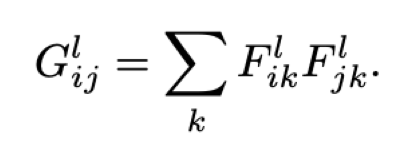 We obtain a stationary, multi-scale representation of the input image, which captures
its texture information but not the global arrangement
We obtain a stationary, multi-scale representation of the input image, which captures
its texture information but not the global arrangement
As with content, we can visualise the information captured by these style feature spaces built on different layers of the network by constructing an image that matches the style representation of a given input image.
Style Transfer Algorithm
1D Convolutional Neural Networks
- CNNs perform well on computer vision problems, due to their ability to operate convolutionally extract features from local input patches.
- The same properties that make CNNs excel at computer vision also make them highly relevant to sequence processing.
- 1D CNNs, typically used with dilated kernels, have been used with great success for audio generation and machine translation.
- They can offer a fast alternative to RNNs for simple tasks such as text classification and timeseries forecasting.
Continuous convolution:
Discrete convolution:
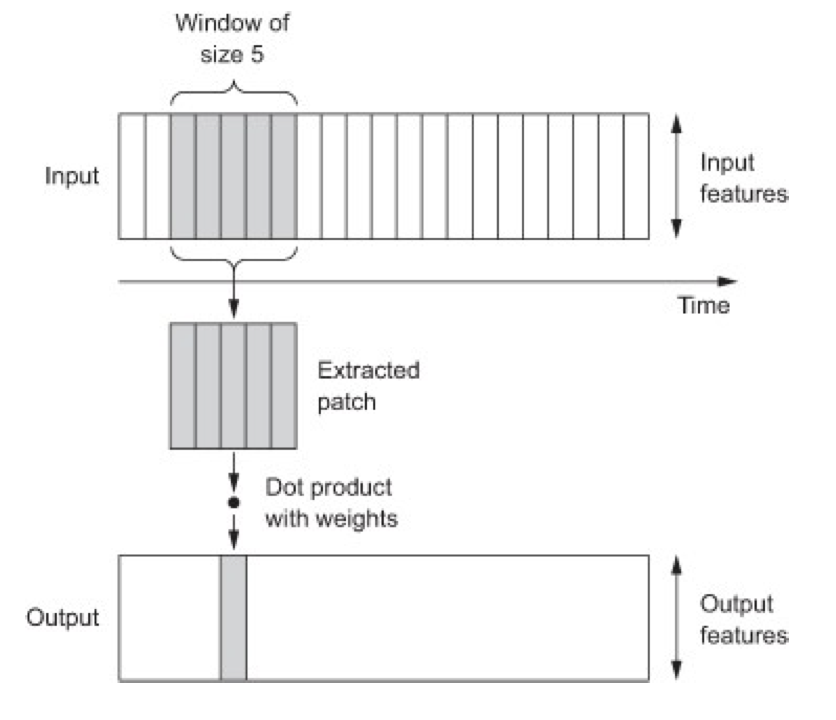
• Combine finite-length filters with 1D patches (subsequences) from sequences
• Each output time step is obtained from a temporal patch in the input sequence
• Convolution layers can recognize local patterns in a sequence
Graph CNNs
- A graph convolutional network (GCN) is a neural network that operates on graphs.
- Given a graph , a GCN takes as input:
- An input feature matrix X of dimension , where N is the number of nodes and F is the number of features per node
- An matrix representation of the graph structure (adjacency matrix A).
- The first hidden layer in the GCN process each node in according to X and A, H=f(X,A)
- H is a node feature matrix where each row is a new feature representation of the node
- At each layer, these features are aggregated to form the next layer’s features using a propagation rule .
Fig. 1: 2D Convolution vs. Graph Convolution.
- (a) 2D Convolution: Analogous to a graph, each pixel in an image is taken as a node where neighbors are determined by the filter size. The 2D convolution takes the weighted average of pixel values of the red node along with its neighbors. The neighbors of a node are ordered and have a fixed size.
- (b) Graph Convolution: To get a hidden representation of the red node, one simple solution of the graph convolutional operation is to take the average value of the node features of the red node along with its neighbors. Different from image data, the neighbors of a node are unordered and variable in size.
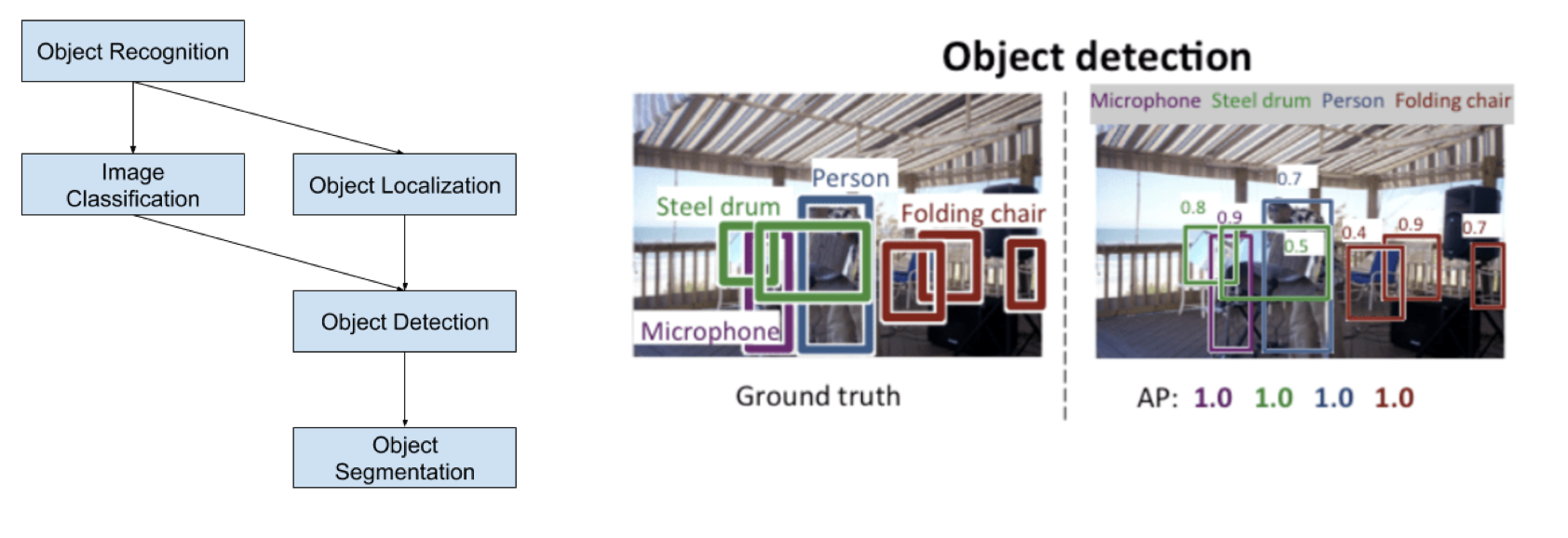
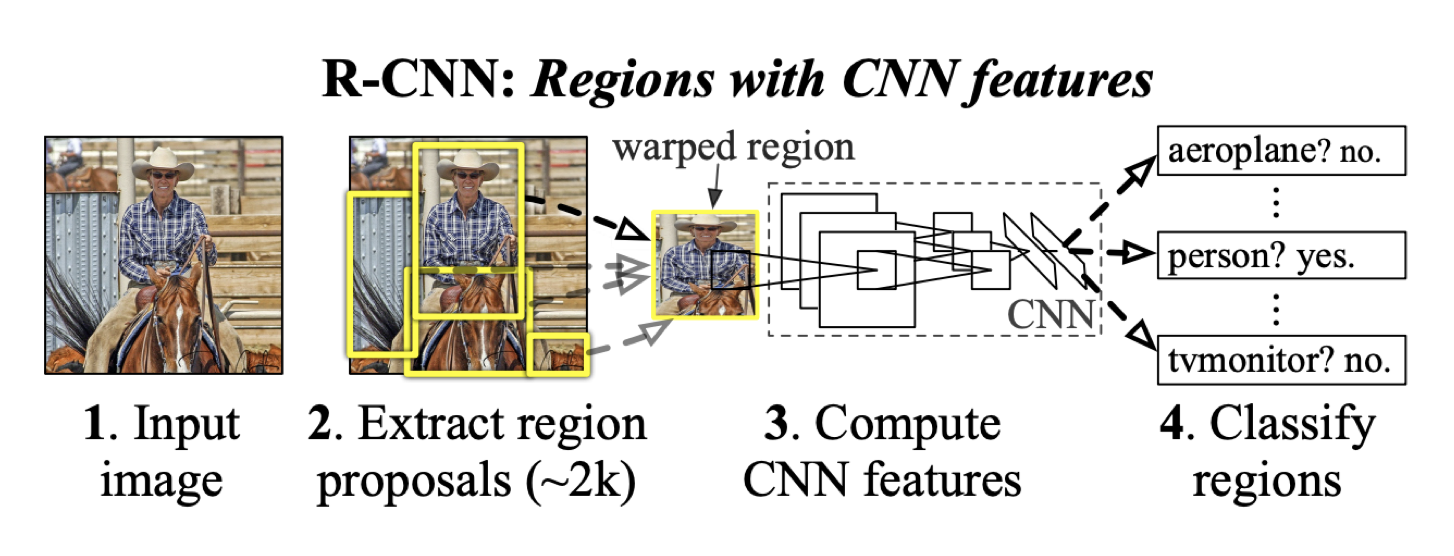
Region-based CNNs (R-CNN) and extensions such as Fast R-CNN and YOLO
(you only look once) are the most dominant approach for object localisation and
recognition.